UK Web Archiveは英国図書館(British Library)が運営している、英国内のウェブサイト等を収集保存するウェブアーカイブです。
英国図書館では2004年から、ウェブサイト管理者の許諾に基づく選択収集を行っていましたが、個別の許諾が必要なため収集可能なサイト数が限られていました。
そこで、2013年4月5日に2013年法定納本図書館(非印刷体)規則が制定されました。これは2003年法定納本図書館法に基づいて策定された、非印刷出版物(non-print publication)の納本に関する規則です。
この規則改正は2013年4月6日に施行され、英国における納本制度の対象に、英国においてインターネット公開されたウェブサイトや電子書籍等が加わりました。
この改正により、英国で発信されたことを示す国別トップレベルドメインである「.uk」をもつウェブサイトを網羅的に収集するバルク収集が開始されました。
バルク収集で収集したウェブサイトのインターネット提供は認められていないため、英国の法定納本図書館内のみでの利用となります。これに対し、選択収集で収集したウェブサイトはインターネットを通じて図書館外でも利用することができます。
英国の法定納本図書館とは、英国図書館、スコットランド国立図書館、ウェールズ国立図書館、オックスフォード大学ボードリアン図書館、ケンブリッジ大学図書館、そしてアイルランドのトリニティ・カレッジ・ダブリン図書館の6館です。
UK Web Archiveは、Heritrixというクローラー(収集ロボット)を使って自動収集を行っています。2004年から許諾を得て選択収集されたウェブサイトは、累計で19,000サイト以上になりました。
パルク収集も含めて収集されたウェブサイトの保存容量は、2017年時点で約500TB (テラバイト)です。 ウェブサイト内の画像や映像、PDFファイルなども含めて収集しているため、年々60TBから70TBずつ増えています。
収集データは、英国図書館(ロンドン)、英国図書館分館(ウェスト・ヨークシャー州ボストンスパ)、スコットランド国立図書館(エジンバラ)及びウェールズ国立図書館(アベリストウィス)の4館に分散して保存されています。各図書館ごとに全データを保存しているため、ある館のデータが破損・消失しても他館のデータを使って自動的に復元することができます。
英国の法定納本図書館内でのみ利用ができるウェブサイトについては、利用者が同時に利用できるのは1館の中で1アクセスのみです。紙へのプリントアウトはできますが、デジタルコピーは認められていません。
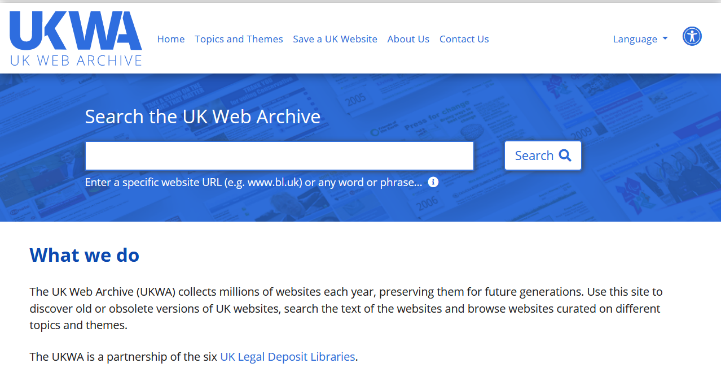
トップページの検索窓(Search the UK Web Archive)に調べたいテーマの単語やURLを入力します。
検索窓はメタデータ検索にのみ対応しており、現在は全文検索には対応していません。
例えば「“London Olympics”」と入力してみましょう。
検索結果(Search Results)が表示されます。
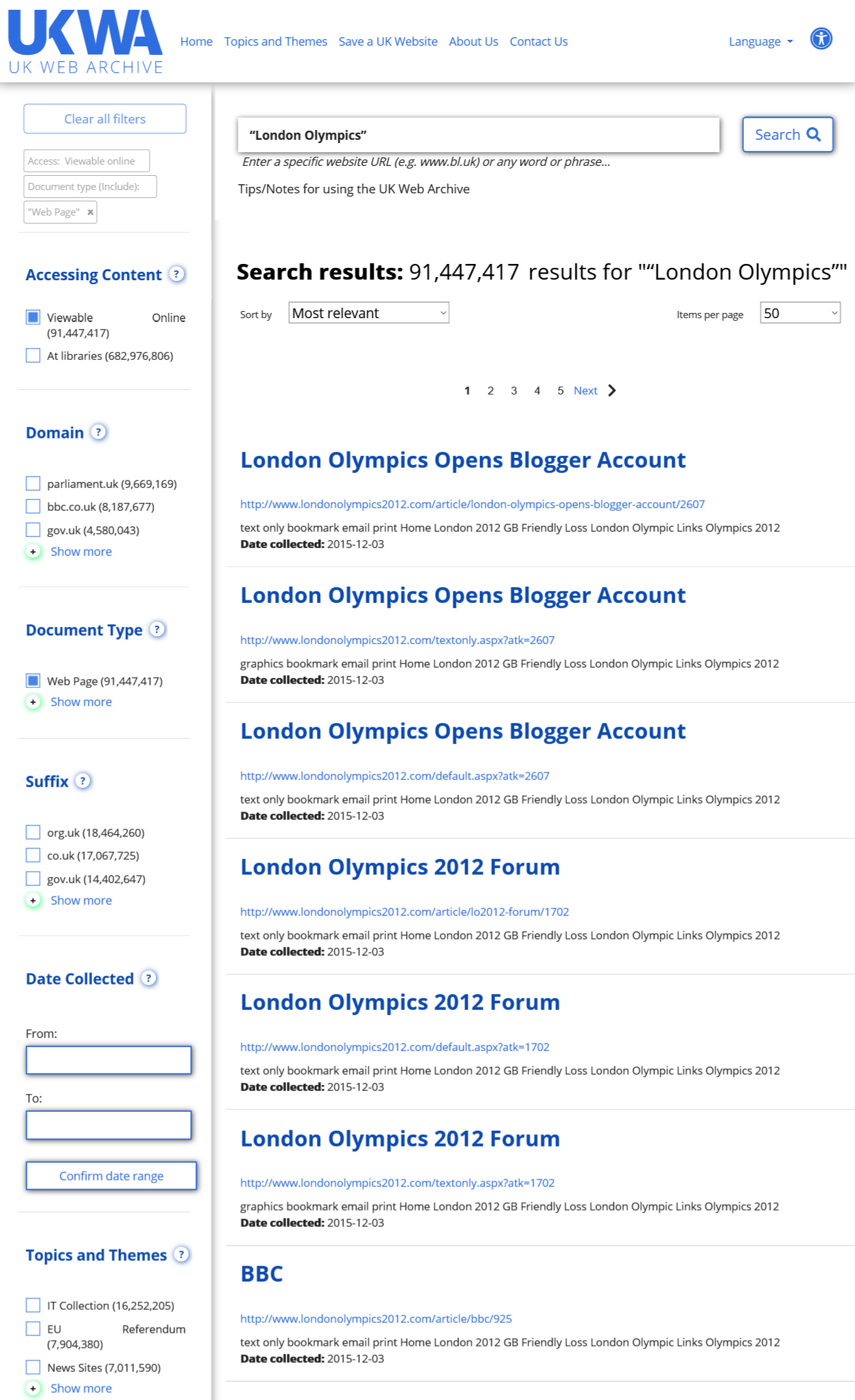 「“London Olympics”」検索結果画面
「“London Olympics”」検索結果画面検索結果画面の左側には様々な絞り込み項目が表示され、検索結果をさらに絞り込むことができます。
コンテンツへのアクセス方法(Accessing Content)は、2種類が表示されます。
インターネットを通じて見ることができるサイト(Viewable Online)と、英国の法定納本図書館内でのみ公開されているサイト(At libraries)です。
さらに、「bbc.co.uk」などのドメイン名(Domain)や、「co.uk」などのドメイン接尾辞(Suffix)で絞り込むこともできます。
また、収集された年月日(Date Collected)で絞り込むこともできます。この年月日はウェブ情報の発信日や更新日ではなく、あくまでも収集年月日なので、注意が必要です。
 ドメインによる絞り込み画面
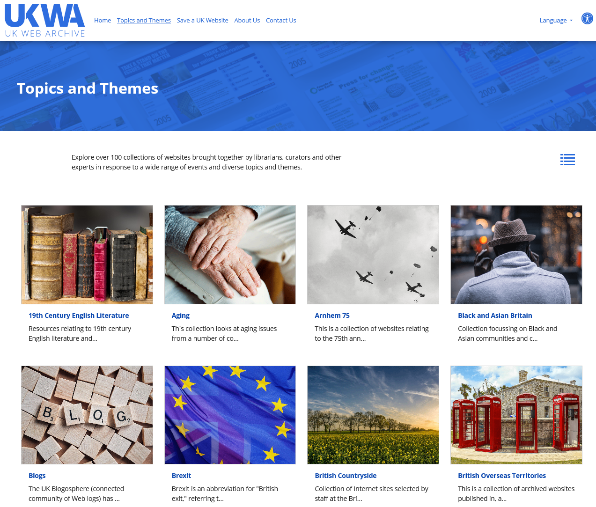
ドメインによる絞り込み画面「Topics and Themes」は、100以上にわたるテーマでウェブサイトを分類したコレクションです。
これは図書館員とキュレーター、各分野の専門家が、テーマに沿ってウェブサイトを選択・分類したもので、テーマ名のアルファベット順にイメージ画像と説明を付して並べられています。
例えば、「Brexit:イギリスの欧州連合離脱」「第一次世界大戦100周年」「気候変動」「サッカー」「魔法」「ビデオゲーム」など、多様なテーマで構成されています。
各テーマへのリンクをクリックすると、テーマに沿って選ばれたウェブサイトの一覧が検索結果として表示されます。 下の「Video Games」の検索結果では、英国の法定納本図書館内でのみ限定公開されるサイト(Viewable only on Library premises)と、インターネットで見られるサイトが並んで表示されています。
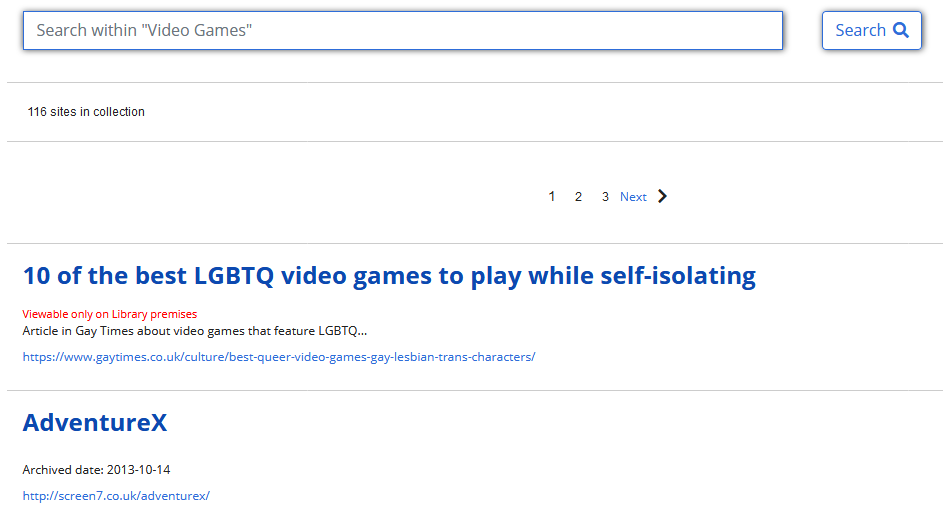 テーマ「Video Games」ウェブサイト一覧画面
テーマ「Video Games」ウェブサイト一覧画面UK Web Archiveで収集したウェブサイト内には多数の電子書籍・電子雑誌に相当する出版物(PDFファイル等)が含まれていますが、膨大なデータの中から必要なコンテンツを見つけ出すことは困難です。
この問題を解決するため、英国図書館では、蔵書検索システムの「Explore the British Library」から、UK Web Archiveで収集したウェブサイト内の一部の出版物を検索できるようにしています。
現在は、検索対象は政府部門の出版物に限られていますが、今後は、シンクタンク、学術研究センター、慈善活動団体などの非営利団体の出版物にも対象を広げることも検討されています。
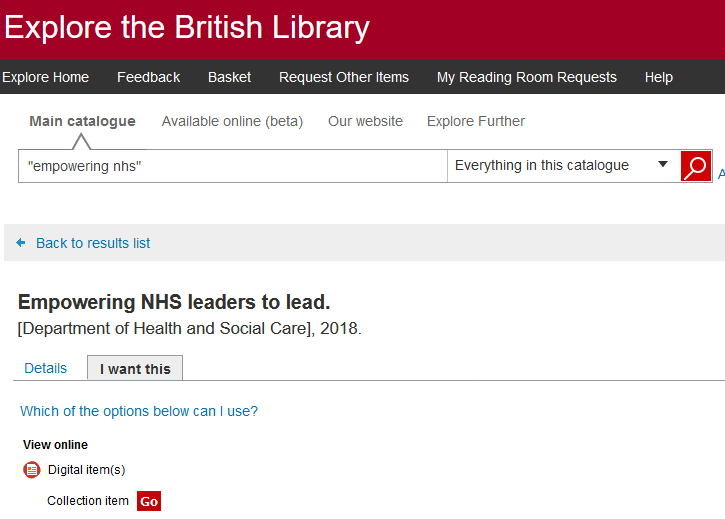
実際に「Explore the British Library」の検索結果を見てみましょう。
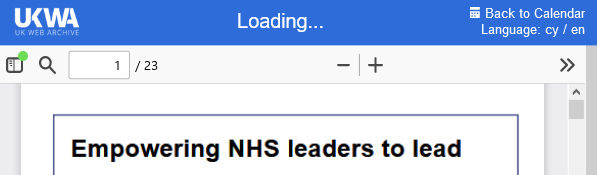
検索結果から、資料の所蔵情報を表示する「I want this」タブをクリックします。同タブでインターネット閲覧可能であることを示す「View online」下の「Digital item(s)」のGOボタンをクリックすると、UK Web Archive内の該当のPDFファイルを閲覧できるようになっています。
検索対象とした出版物のメタデータを1件ずつ「Explore the British Library」に登録することによって、こうした検索が可能となっています。
なお、出版物のメタデータを作成するには手間とコストがかかることから、英国図書館では効率的にメタデータを作成することができるように「Digital Documents Harvesting and Processing Tool」(DDHAPT)というツールの開発も行っています。
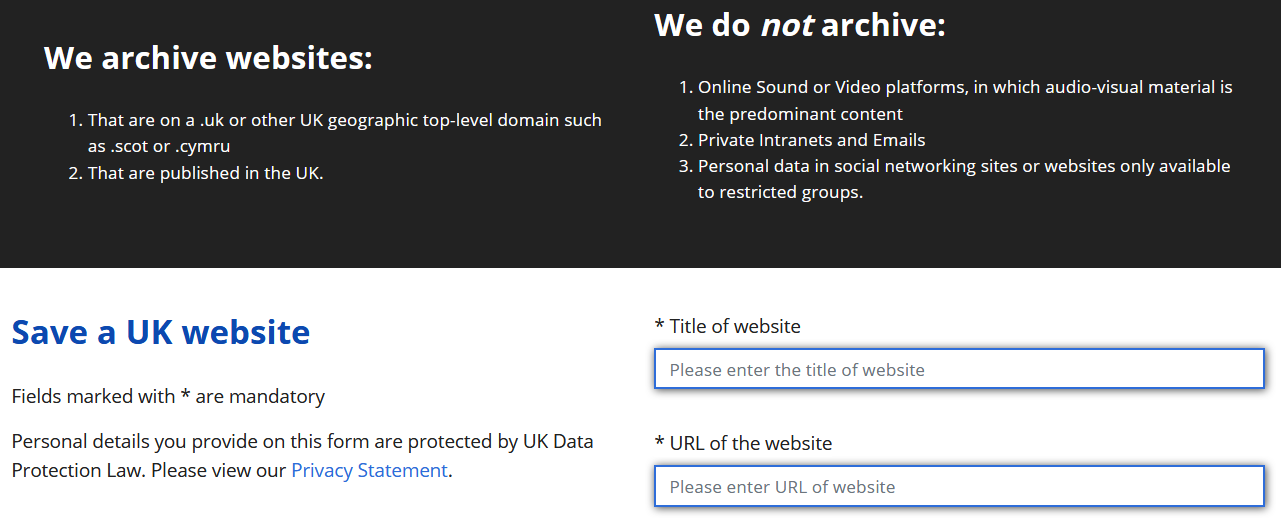
UK Web Archiveでは、選択収集とバルク収集とを組み合わせて、英国内のウェブサイトを幅広く収集しようと努めていますが、依然として収集できないサイトも数多くあります。
そのようなサイトを補うべく、英国関連のドメインを持つウェブサイト(「.uk」「.cymru」「.scot」等)を対象とした「Save a UK Website」という専用ページが設けられています。
商用目的の音楽・動画のプラットフォームやイントラネット、電子メールなどは対象としませんが、公的機関のサイトから個人的なサイトまで多様なウェブサイトを一般から広く募ることで、より多くの英国内ウェブサイトの収集につなげる取組みを行っています。
(最終更新日:2021/4/14)