6. 差分収集
ウェブアーカイブでは、同じウェブサイトを定期的に収集していきます。そのため、収集するファイルのなかには、過去に収集した時点から更新されているファイルもあれば、過去と全く同じファイルもあります。
収集するたびに全てのファイルを保存する方法をフル収集と言い、変更があったファイルのみを保存する方法を差分収集と言います。
フル収集では、同じファイルを重複して保存することになりますので、必要なストレージ(電子書庫)の容量が大きくなります。一方、差分収集では同じファイルは保存しないため、ストレージを節約することができます。
フル収集と差分収集のしくみ
フル収集と差分収集について、模式図で詳しく見てみましょう。
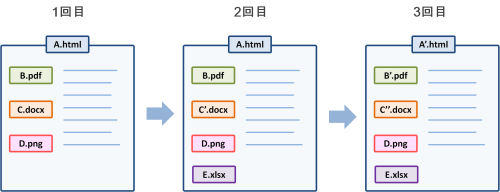 オリジナルのウェブサイト
オリジナルのウェブサイト
オリジナルのウェブサイトが以下であると仮定します。
- ・1回目の収集時には、A.html、B.pdf、C.docx、D.pngが存在。
- ・2回目の収集時には、A.html、B.pdf、D.pngには変更がなく、C'.docxが変更、E.xlsxが追加。
- ・3回目の収集時には、D.pngとE.xlsxには変更がなく、A'.html、B'.pdf、C''.docxが変更。
- (「'」はファイル名の変更ではなく、データ内容の変更を表す。)
フル収集
 フル収集のイメージ
フル収集のイメージ
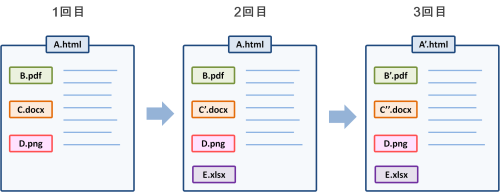
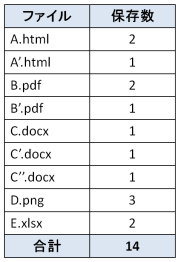 フル収集時のファイル保存数
フル収集時のファイル保存数
フル収集では、ファイル変更の有無に関わらず、収集するたび全てのファイルを保存します。そのため、重複して保存されるファイルがあり、ファイル数の合計は「14」になります。
差分収集
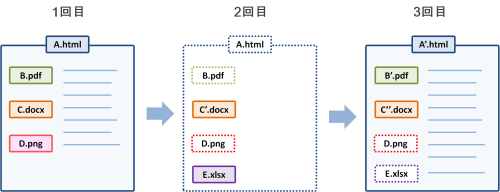 差分収集のイメージ
差分収集のイメージ
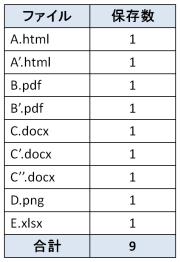 差分収集時のファイル保存数
差分収集時のファイル保存数
差分収集では、過去に収集したのと同じファイルがある場合、そのファイルは保存しません。上掲の図「差分収集のイメージ」のように、同一ファイルの点線部分は保存せずに、実線部分のみを保存します。
その結果、各ファイルを保存する回数は1回のみで、ファイル保存数の合計は「9」になります。フル収集時の保存数「14」と比べると、少なくなっているのが分かります。
ハッシュ値による比較
差分収集において、同一ファイルかどうかの判定は、ハッシュ値を比較して行います。
ハッシュ値とは、電子データを一定の計算方法(ハッシュ関数)で操作して得られる値のことです。異なる電子データのハッシュ値が同じになることは殆どないため、電子データにおける指紋に例えられます。電子データに僅かでも変更を加えると、ハッシュ値も変わります。
新たに収集したファイルを保存する際には、前回の収集ログに同名のファイルが存在しなければ、新たに保存します。同名のファイルが存在する場合には、ハッシュ値を比較して異なる場合のみ保存します。
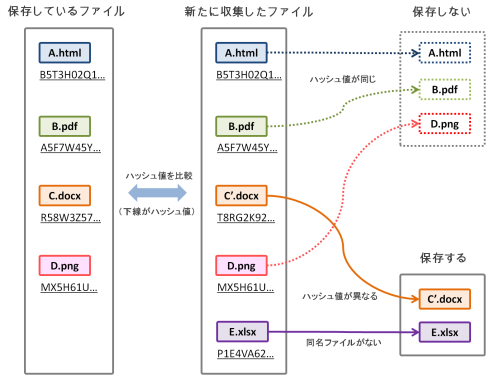 ハッシュ値の比較
ハッシュ値の比較
差分収集したウェブサイトの再現
差分収集で保存したウェブサイトを再現する際、収集した時点のファイルを保存している場合はそのファイルを表示し、その時点のファイルがない場合は、一番近い過去に保存した同名のファイルを表示します。これは、収集の際にハッシュ値を比較して同値だったファイルですので、収集時点が異なっていてもオリジナルの状態を保ったままで再現することができます。
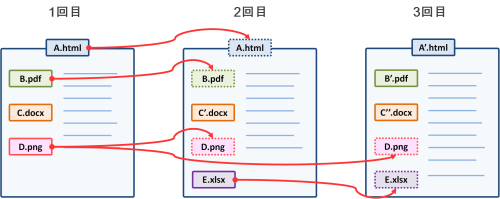 差分収集したウェブサイトの再現
差分収集したウェブサイトの再現
ストレージの節約効果
差分収集をすることで、保存するファイルを少なくすることができ、ファイルの保存に必要なストレージの容量を削減することができます。
「収集する頻度」で紹介したように、WARPでは国の機関を毎月、その他を概ね年4回の頻度で収集しています。これらを差分収集した場合、フル収集に比べて約7割の削減効果があることが分かっています。つまり、必要なストレージの容量が、フル収集の3割程度で済みます。
このように、膨大なデータを扱うウェブアーカイブにおいては、差分収集がストレージの節約に大きな効果を発揮するのです。
(最終更新日:2014/10/1)