Mechanism of Web Archiving

We clearly explain the mechanism of web archiving. (The articles are written in Japanese.)
Mechanism of Web Archiving
- What is Web Archiving?
- Life Cycle of Web Archiving
- How to Harvest Websites
- Granularity of Managing Harvested Pages
- Harvesting Frequency
- Deduplication
- Organization of Archived Websites
- Long-term Preservation of Archived Websites
- Providing Access to Archived Websites
- Technical Challenges of Web Archiving
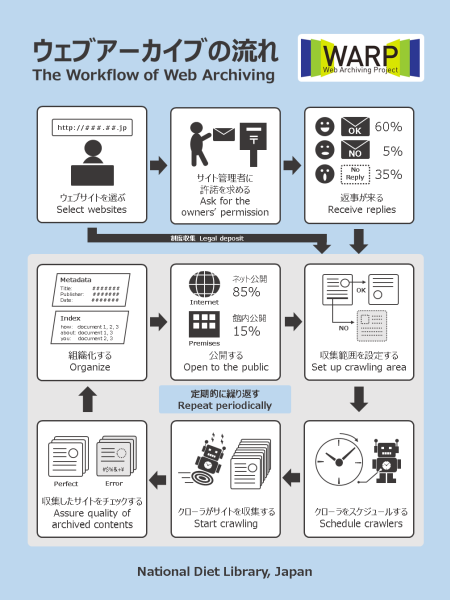
The Workflow of Web Archiving
The following figure simply shows the workflow of web archiving.